
robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
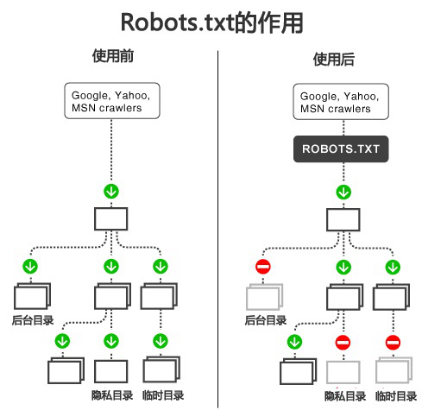
robots.txt文件特点:必须放置在一个站点的根目录下,而且文件名必须全部小写。
robots.txt
文件在SEO中作用:鉴 于网络安全与隐私的考虑,搜索引擎遵循robots.txt协议。通过根目录中创建的纯文本文件robots.txt,
网站可以声明不想被robots访问的部分。每个网站都可以自主控制网站是否愿意被搜索引擎收录,或者指定搜索引擎只收录指定的内容。当一个搜索引擎的爬
虫访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果该文件不存在,那么爬虫就沿着链接抓取,如果存在,爬虫就会按照该文件
中的内容来确定访问的范围。
robots.txt文件的格式:
User-agent: 定义搜索引擎的类型。
Disallow: 定义禁止搜索引擎收录的地址。
Allow: 定义允许搜索引擎收录的地址。
格式如:User-agent: * Disallow: /index.html Disallow: /index.php? Disallow: /html/ allow:/search.html
robots.txt文件的写法:
User-agent: * 这里的“*”代表的所有的搜索引擎种类,“*”是一个通配符。允许所有的搜索引擎来收录,包括百度、google、yahoo等 。
Disallow: /web/ 这里定义是禁止爬寻web目录下面的目录。
Disallow: /dedecms/ 这里定义是禁止爬寻dedecms目录下面的目录 。
Disallow: /ppc/ 这里定义是禁止爬寻ppc目录下面的目录 。
Disallow: /SEO 是屏蔽A目录下的所有文件,包括文件和子目录,还屏蔽 /SEO*.*的文件。
Disallow: /seo-study/*.htm 禁止访问/seo-study/目录下的所有以".htm"为后缀的URL(包含子目录)。
Disallow: /*?* 禁止访问网站中所有带“?”的URL。
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片。
Disallow:/dedecms-label/arclist.html 禁止爬取dedecms-label文件夹下面的arclist.html文件。
Allow:/linxige/ 这里定义是允许爬寻linxige目录下面的目录。
Allow: /seo 这里定义是允许爬寻seo的整个目录。
Allow: .htm$ 仅允许访问以".htm"为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片。
常用的搜索引擎类型有: (User-agent区分大小写)
1.google蜘蛛:Googlebot Google Adsense蜘蛛:Mediapartners-Google 2.百度蜘蛛:Baiduspider 3.360蜘蛛:360Spider
4.yahoo蜘蛛:Yahoo!Slurp 5.alexa蜘蛛:ia_archiver 6.bing蜘蛛:MSNbot 7.Soso蜘蛛:Sosospider, 8.有道蜘蛛:YoudaoBot等
通过robots.txt可以删除被收录的内容:
1、当你的网页已被收录,但想用robots.txt删除掉,一般需要1-2个月。
2、结合Google网站管理员工具,你可以马上删除被Google收录的网页。
3、结合百度的站长平台,通过这里可以尽快删除被百度收录的页面:http://www.baidu.com/search/badlink_help.html
使用robots.txt应遵循几个原则:
1、不要屏蔽首页的后缀,比如:index.php,index.html 等;
2、不要写太多带星号的,尽量简洁一些,我们看百度和Google的robtos.txt带星号的写法几乎没有,太多带星号的,就可能存在误伤;
3、不用什么都屏蔽,某些页面即使被收录了也不影响什么的,就建议可以不用屏蔽。
注:搜索引擎遵守robots的相关协议,请注意区分您不想被抓取或收录的目录的大小写,我们会对robots中所写的文件和您不想被抓取和收录的目录做精确匹配,否则robots协议无法生效。






 粤公网安备 44010502000039号 ICP/ISP 粤B2-20051039
粤公网安备 44010502000039号 ICP/ISP 粤B2-20051039


 400-888-6638 83226239
400-888-6638 83226239



